Losses¶
sentence_transformers.losses defines different loss functions that can be used to fine-tune embedding models on training data. The choice of loss function plays a critical role when fine-tuning the model. It determines how well our embedding model will work for the specific downstream task.
Sadly, there is no “one size fits all” loss function. Which loss function is suitable depends on the available training data and on the target task. Consider checking out the Loss Overview to help narrow down your choice of loss function(s).
BatchAllTripletLoss¶
-
class
sentence_transformers.losses.BatchAllTripletLoss(model: sentence_transformers.SentenceTransformer.SentenceTransformer, distance_metric=<function BatchHardTripletLossDistanceFunction.eucledian_distance>, margin: float = 5)¶ BatchAllTripletLoss takes a batch with (sentence, label) pairs and computes the loss for all possible, valid triplets, i.e., anchor and positive must have the same label, anchor and negative a different label. The labels must be integers, with same label indicating sentences from the same class. Your train dataset must contain at least 2 examples per label class.
- Parameters
model – SentenceTransformer model
distance_metric – Function that returns a distance between two embeddings. The class SiameseDistanceMetric contains pre-defined metrics that can be used.
margin – Negative samples should be at least margin further apart from the anchor than the positive.
- References:
Source: https://github.com/NegatioN/OnlineMiningTripletLoss/blob/master/online_triplet_loss/losses.py
Paper: In Defense of the Triplet Loss for Person Re-Identification, https://arxiv.org/abs/1703.07737
Blog post: https://omoindrot.github.io/triplet-loss
- Requirements:
Each sentence must be labeled with a class.
Your dataset must contain at least 2 examples per labels class.
- Relations:
BatchHardTripletLossuses only the hardest positive and negative samples, rather than all possible, valid triplets.BatchHardSoftMarginTripletLossuses only the hardest positive and negative samples, rather than all possible, valid triplets. Also, it does not require setting a margin.BatchSemiHardTripletLossuses only semi-hard triplets, valid triplets, rather than all possible, valid triplets.
- Inputs:
Texts
Labels
single sentences
class
- Example:
from sentence_transformers import SentenceTransformer, losses from sentence_transformers.readers import InputExample from torch.utils.data import DataLoader model = SentenceTransformer('distilbert-base-nli-mean-tokens') train_examples = [ InputExample(texts=['Sentence from class 0'], label=0), InputExample(texts=['Another sentence from class 0'], label=0), InputExample(texts=['Sentence from class 1'], label=1), InputExample(texts=['Sentence from class 2'], label=2), ] train_batch_size = 2 train_dataloader = DataLoader(train_examples, shuffle=True, batch_size=train_batch_size) train_loss = losses.BatchAllTripletLoss(model=model) model.fit( train_objectives=[(train_dataloader, train_loss)], epochs=10, )
BatchHardSoftMarginTripletLoss¶
-
class
sentence_transformers.losses.BatchHardSoftMarginTripletLoss(model: sentence_transformers.SentenceTransformer.SentenceTransformer, distance_metric=<function BatchHardTripletLossDistanceFunction.eucledian_distance>)¶ BatchHardSoftMarginTripletLoss takes a batch with (sentence, label) pairs and computes the loss for all possible, valid triplets, i.e., anchor and positive must have the same label, anchor and negative a different label. The labels must be integers, with same label indicating sentences from the same class. Your train dataset must contain at least 2 examples per label class. This soft-margin variant does not require setting a margin.
- Parameters
model – SentenceTransformer model
distance_metric – Function that returns a distance between two embeddings. The class SiameseDistanceMetric contains pre-defined metrics that can be used.
- Definitions:
- Easy triplets
Triplets which have a loss of 0 because
distance(anchor, positive) + margin < distance(anchor, negative).- Hard triplets
Triplets where the negative is closer to the anchor than the positive, i.e.,
distance(anchor, negative) < distance(anchor, positive).- Semi-hard triplets
Triplets where the negative is not closer to the anchor than the positive, but which still have a positive loss, i.e.,
distance(anchor, positive) < distance(anchor, negative) + margin.
- References:
Source: https://github.com/NegatioN/OnlineMiningTripletLoss/blob/master/online_triplet_loss/losses.py
Paper: In Defense of the Triplet Loss for Person Re-Identification, https://arxiv.org/abs/1703.07737
Blog post: https://omoindrot.github.io/triplet-loss
- Requirements:
Each sentence must be labeled with a class.
Your dataset must contain at least 2 examples per labels class.
Your dataset should contain hard positives and negatives.
- Relations:
BatchHardTripletLossuses a user-specified margin, while this loss does not require setting a margin.
- Inputs:
Texts
Labels
single sentences
class
- Example:
from sentence_transformers import SentenceTransformer, losses from sentence_transformers.readers import InputExample from torch.utils.data import DataLoader model = SentenceTransformer('distilbert-base-nli-mean-tokens') train_examples = [ InputExample(texts=['Sentence from class 0'], label=0), InputExample(texts=['Another sentence from class 0'], label=0), InputExample(texts=['Sentence from class 1'], label=1), InputExample(texts=['Sentence from class 2'], label=2) ] train_batch_size = 2 train_dataloader = DataLoader(train_examples, shuffle=True, batch_size=train_batch_size) train_loss = losses.BatchHardSoftMarginTripletLoss(model=model) model.fit( train_objectives=[(train_dataloader, train_loss)], epochs=10, )
BatchHardTripletLoss¶
-
class
sentence_transformers.losses.BatchHardTripletLoss(model: sentence_transformers.SentenceTransformer.SentenceTransformer, distance_metric=<function BatchHardTripletLossDistanceFunction.eucledian_distance>, margin: float = 5)¶ BatchHardTripletLoss takes a batch with (sentence, label) pairs and computes the loss for all possible, valid triplets, i.e., anchor and positive must have the same label, anchor and negative a different label. It then looks for the hardest positive and the hardest negatives. The labels must be integers, with same label indicating sentences from the same class. Your train dataset must contain at least 2 examples per label class.
- Parameters
model – SentenceTransformer model
distance_metric – Function that returns a distance between two embeddings. The class SiameseDistanceMetric contains pre-defined metrics that can be used
margin – Negative samples should be at least margin further apart from the anchor than the positive.
- Definitions:
- Easy triplets
Triplets which have a loss of 0 because
distance(anchor, positive) + margin < distance(anchor, negative).- Hard triplets
Triplets where the negative is closer to the anchor than the positive, i.e.,
distance(anchor, negative) < distance(anchor, positive).- Semi-hard triplets
Triplets where the negative is not closer to the anchor than the positive, but which still have a positive loss, i.e.,
distance(anchor, positive) < distance(anchor, negative) + margin.
- References:
Source: https://github.com/NegatioN/OnlineMiningTripletLoss/blob/master/online_triplet_loss/losses.py
Paper: In Defense of the Triplet Loss for Person Re-Identification, https://arxiv.org/abs/1703.07737
Blog post: https://omoindrot.github.io/triplet-loss
- Requirements:
Each sentence must be labeled with a class.
Your dataset must contain at least 2 examples per labels class.
Your dataset should contain hard positives and negatives.
- Inputs:
Texts
Labels
single sentences
class
- Relations:
BatchAllTripletLossuses all possible, valid triplets, rather than only the hardest positive and negative samples.BatchSemiHardTripletLossuses only semi-hard triplets, valid triplets, rather than only the hardest positive and negative samples.BatchHardSoftMarginTripletLossdoes not require setting a margin, while this loss does.
- Example:
from sentence_transformers import SentenceTransformer, losses from sentence_transformers.readers import InputExample from torch.utils.data import DataLoader model = SentenceTransformer('distilbert-base-nli-mean-tokens') train_examples = [ InputExample(texts=['Sentence from class 0'], label=0), InputExample(texts=['Another sentence from class 0'], label=0), InputExample(texts=['Sentence from class 1'], label=1), InputExample(texts=['Sentence from class 2'], label=2) ] train_batch_size = 2 train_dataloader = DataLoader(train_examples, shuffle=True, batch_size=train_batch_size) train_loss = losses.BatchHardTripletLoss(model=model) model.fit( train_objectives=[(train_dataloader, train_loss)], epochs=10, )
BatchSemiHardTripletLoss¶
-
class
sentence_transformers.losses.BatchSemiHardTripletLoss(model: sentence_transformers.SentenceTransformer.SentenceTransformer, distance_metric=<function BatchHardTripletLossDistanceFunction.eucledian_distance>, margin: float = 5)¶ BatchSemiHardTripletLoss takes a batch with (label, sentence) pairs and computes the loss for all possible, valid triplets, i.e., anchor and positive must have the same label, anchor and negative a different label. It then looks for the semi hard positives and negatives. The labels must be integers, with same label indicating sentences from the same class. Your train dataset must contain at least 2 examples per label class.
- Parameters
model – SentenceTransformer model
distance_metric – Function that returns a distance between two embeddings. The class SiameseDistanceMetric contains pre-defined metrics that can be used
margin – Negative samples should be at least margin further apart from the anchor than the positive.
- Definitions:
- Easy triplets
Triplets which have a loss of 0 because
distance(anchor, positive) + margin < distance(anchor, negative).- Hard triplets
Triplets where the negative is closer to the anchor than the positive, i.e.,
distance(anchor, negative) < distance(anchor, positive).- Semi-hard triplets
Triplets where the negative is not closer to the anchor than the positive, but which still have a positive loss, i.e.,
distance(anchor, positive) < distance(anchor, negative) + margin.
- References:
Source: https://github.com/NegatioN/OnlineMiningTripletLoss/blob/master/online_triplet_loss/losses.py
Paper: In Defense of the Triplet Loss for Person Re-Identification, https://arxiv.org/abs/1703.07737
Blog post: https://omoindrot.github.io/triplet-loss
- Requirements:
Each sentence must be labeled with a class.
Your dataset must contain at least 2 examples per labels class.
Your dataset should contain semi hard positives and negatives.
- Relations:
BatchHardTripletLossuses only the hardest positive and negative samples, rather than only semi hard positive and negatives.BatchAllTripletLossuses all possible, valid triplets, rather than only semi hard positive and negatives.BatchHardSoftMarginTripletLossuses only the hardest positive and negative samples, rather than only semi hard positive and negatives.
Also, it does not require setting a margin.
- Inputs:
Texts
Labels
single sentences
class
- Example:
from sentence_transformers import SentenceTransformer, losses from sentence_transformers.readers import InputExample from torch.utils.data import DataLoader model = SentenceTransformer('distilbert-base-nli-mean-tokens') train_examples = [ InputExample(texts=['Sentence from class 0'], label=0), InputExample(texts=['Another sentence from class 0'], label=0), InputExample(texts=['Sentence from class 1'], label=1), InputExample(texts=['Sentence from class 2'], label=2) ] train_batch_size = 2 train_dataloader = DataLoader(train_examples, shuffle=True, batch_size=train_batch_size) train_loss = losses.BatchSemiHardTripletLoss(model=model) model.fit( train_objectives=[(train_dataloader, train_loss)], epochs=10, )
ContrastiveLoss¶
-
class
sentence_transformers.losses.ContrastiveLoss(model: sentence_transformers.SentenceTransformer.SentenceTransformer, distance_metric=<function SiameseDistanceMetric.<lambda>>, margin: float = 0.5, size_average: bool = True)¶ Contrastive loss. Expects as input two texts and a label of either 0 or 1. If the label == 1, then the distance between the two embeddings is reduced. If the label == 0, then the distance between the embeddings is increased.
- Parameters
model – SentenceTransformer model
distance_metric – Function that returns a distance between two embeddings. The class SiameseDistanceMetric contains pre-defined metrices that can be used
margin – Negative samples (label == 0) should have a distance of at least the margin value.
size_average – Average by the size of the mini-batch.
- References:
- Requirements:
(anchor, positive/negative) pairs
- Relations:
OnlineContrastiveLossis similar, but uses hard positive and hard negative pairs.
It often yields better results.
- Inputs:
Texts
Labels
(anchor, positive/negative) pairs
1 if positive, 0 if negative
- Example:
from sentence_transformers import SentenceTransformer, losses from sentence_transformers.readers import InputExample from torch.utils.data import DataLoader model = SentenceTransformer('all-MiniLM-L6-v2') train_examples = [ InputExample(texts=['This is a positive pair', 'Where the distance will be minimized'], label=1), InputExample(texts=['This is a negative pair', 'Their distance will be increased'], label=0), ] train_dataloader = DataLoader(train_examples, shuffle=True, batch_size=2) train_loss = losses.ContrastiveLoss(model=model) model.fit( [(train_dataloader, train_loss)], epochs=10, )
OnlineContrastiveLoss¶
-
class
sentence_transformers.losses.OnlineContrastiveLoss(model: sentence_transformers.SentenceTransformer.SentenceTransformer, distance_metric=<function SiameseDistanceMetric.<lambda>>, margin: float = 0.5)¶ This Online Contrastive loss is similar to
ConstrativeLoss, but it selects hard positive (positives that are far apart) and hard negative pairs (negatives that are close) and computes the loss only for these pairs. This loss often yields better performances than ContrastiveLoss.- Parameters
model – SentenceTransformer model
distance_metric – Function that returns a distance between two embeddings. The class SiameseDistanceMetric contains pre-defined metrics that can be used
margin – Negative samples (label == 0) should have a distance of at least the margin value.
- References:
- Requirements:
(anchor, positive/negative) pairs
Data should include hard positives and hard negatives
- Relations:
ContrastiveLossis similar, but does not use hard positive and hard negative pairs.
OnlineContrastiveLossoften yields better results.- Inputs:
Texts
Labels
(anchor, positive/negative) pairs
1 if positive, 0 if negative
- Example:
from sentence_transformers import SentenceTransformer, losses, InputExample from torch.utils.data import DataLoader model = SentenceTransformer('all-MiniLM-L6-v2') train_examples = [ InputExample(texts=['This is a positive pair', 'Where the distance will be minimized'], label=1), InputExample(texts=['This is a negative pair', 'Their distance will be increased'], label=0), ] train_dataloader = DataLoader(train_examples, shuffle=True, batch_size=2) train_loss = losses.OnlineContrastiveLoss(model=model) model.fit( [(train_dataloader, train_loss)], epochs=10, )
ContrastiveTensionLoss¶
-
class
sentence_transformers.losses.ContrastiveTensionLoss(model: sentence_transformers.SentenceTransformer.SentenceTransformer)¶ This loss expects only single sentences, without any labels. Positive and negative pairs are automatically created via random sampling, such that a positive pair consists of two identical sentences and a negative pair consists of two different sentences. An independent copy of the encoder model is created, which is used for encoding the first sentence of each pair. The original encoder model encodes the second sentence. The embeddings are compared and scored using the generated labels (1 if positive, 0 if negative) using the binary cross entropy objective.
Note that you must use the ContrastiveTensionDataLoader for this loss. The pos_neg_ratio of the ContrastiveTensionDataLoader can be used to determine the number of negative pairs per positive pair.
Generally,
ContrastiveTensionLossInBatchNegativesis recommended over this loss, as it gives a stronger training signal.- Parameters
model – SentenceTransformer model
- References:
Semantic Re-Tuning with Contrastive Tension: https://openreview.net/pdf?id=Ov_sMNau-PF
- Relations:
ContrastiveTensionLossInBatchNegativesuses in-batch negative sampling, which gives a stronger training signal than this loss.
- Inputs:
Texts
Labels
single sentences
none
- Example:
from sentence_transformers import SentenceTransformer, losses from sentence_transformers.losses import ContrastiveTensionDataLoader model = SentenceTransformer('all-MiniLM-L6-v2') train_examples = [ 'This is the 1st sentence', 'This is the 2nd sentence', 'This is the 3rd sentence', 'This is the 4th sentence', 'This is the 5th sentence', 'This is the 6th sentence', 'This is the 7th sentence', 'This is the 8th sentence', 'This is the 9th sentence', 'This is the final sentence', ] train_dataloader = ContrastiveTensionDataLoader(train_examples, batch_size=3, pos_neg_ratio=3) train_loss = losses.ContrastiveTensionLoss(model=model) model.fit( [(train_dataloader, train_loss)], epochs=10, )
Initializes internal Module state, shared by both nn.Module and ScriptModule.
ContrastiveTensionLossInBatchNegatives¶
-
class
sentence_transformers.losses.ContrastiveTensionLossInBatchNegatives(model: sentence_transformers.SentenceTransformer.SentenceTransformer, scale: float = 20.0, similarity_fct=<function cos_sim>)¶ This loss expects only single sentences, without any labels. Positive and negative pairs are automatically created via random sampling, such that a positive pair consists of two identical sentences and a negative pair consists of two different sentences. An independent copy of the encoder model is created, which is used for encoding the first sentence of each pair. The original encoder model encodes the second sentence. Unlike
ContrastiveTensionLoss, this loss uses the batch negative sampling strategy, i.e. the negative pairs are sampled from the batch. Using in-batch negative sampling gives a stronger training signal than the originalContrastiveTensionLoss. The performance usually increases with increasing batch sizes.Note that you should not use the ContrastiveTensionDataLoader for this loss, but just a normal DataLoader with InputExample instances. The two texts of each InputExample instance should be identical.
- Parameters
model – SentenceTransformer model
scale – Output of similarity function is multiplied by scale value
similarity_fct – similarity function between sentence embeddings. By default, cos_sim. Can also be set to dot product (and then set scale to 1)
- References:
Semantic Re-Tuning with Contrastive Tension: https://openreview.net/pdf?id=Ov_sMNau-PF
- Relations:
ContrastiveTensionLossdoes not select negative pairs in-batch, resulting in a weaker training signal than this loss.
- Inputs:
Texts
Labels
(anchor, anchor) pairs
none
- Example:
from sentence_transformers import SentenceTransformer, losses from torch.utils.data import DataLoader model = SentenceTransformer('all-MiniLM-L6-v2') train_examples = [ InputExample(texts=['This is a positive pair', 'Where the distance will be minimized'], label=1), InputExample(texts=['This is a negative pair', 'Their distance will be increased'], label=0), ] train_examples = [ InputExample(texts=['This is the 1st sentence', 'This is the 1st sentence']), InputExample(texts=['This is the 2nd sentence', 'This is the 2nd sentence']), InputExample(texts=['This is the 3rd sentence', 'This is the 3rd sentence']), InputExample(texts=['This is the 4th sentence', 'This is the 4th sentence']), InputExample(texts=['This is the 5th sentence', 'This is the 5th sentence']), ] train_dataloader = DataLoader(train_examples, shuffle=True, batch_size=32) train_loss = losses.ContrastiveTensionLossInBatchNegatives(model=model) model.fit( [(train_dataloader, train_loss)], epochs=10, )
CoSENTLoss¶
-
class
sentence_transformers.losses.CoSENTLoss(model: sentence_transformers.SentenceTransformer.SentenceTransformer, scale: float = 20.0, similarity_fct=<function pairwise_cos_sim>)¶ This class implements CoSENT (Cosine Sentence) loss. It expects that each of the InputExamples consists of a pair of texts and a float valued label, representing the expected similarity score between the pair.
It computes the following loss function:
loss = logsum(1+exp(s(k,l)-s(i,j))+exp...), where(i,j)and(k,l)are any of the input pairs in the batch such that the expected similarity of(i,j)is greater than(k,l). The summation is over all possible pairs of input pairs in the batch that match this condition.Anecdotal experiments show that this loss function produces a more powerful training signal than
CosineSimilarityLoss, resulting in faster convergence and a final model with superior performance. Consequently, CoSENTLoss may be used as a drop-in replacement forCosineSimilarityLossin any training script.- Parameters
model – SentenceTransformerModel
similarity_fct – Function to compute the PAIRWISE similarity between embeddings. Default is
util.pairwise_cos_sim.scale – Output of similarity function is multiplied by scale value. Represents the inverse temperature.
- References:
For further details, see: https://kexue.fm/archives/8847
- Requirements:
Sentence pairs with corresponding similarity scores in range of the similarity function. Default is [-1,1].
- Relations:
AnglELossis CoSENTLoss withpairwise_angle_simas the metric, rather thanpairwise_cos_sim.CosineSimilarityLossseems to produce a weaker training signal than CoSENTLoss. In our experiments, CoSENTLoss is recommended.
- Inputs:
Texts
Labels
(sentence_A, sentence_B) pairs
float similarity score
- Example:
from sentence_transformers import SentenceTransformer, losses from sentence_transformers.readers import InputExample model = SentenceTransformer('bert-base-uncased') train_examples = [InputExample(texts=['My first sentence', 'My second sentence'], label=1.0), InputExample(texts=['My third sentence', 'Unrelated sentence'], label=0.3)] train_dataloader = DataLoader(train_examples, shuffle=True, batch_size=train_batch_size) train_loss = losses.CoSENTLoss(model=model)
AnglELoss¶
-
class
sentence_transformers.losses.AnglELoss(model: sentence_transformers.SentenceTransformer.SentenceTransformer, scale: float = 20.0)¶ This class implements AnglE (Angle Optimized) loss. This is a modification of
CoSENTLoss, designed to address the following issue: The cosine function’s gradient approaches 0 as the wave approaches the top or bottom of its form. This can hinder the optimization process, so AnglE proposes to instead optimize the angle difference in complex space in order to mitigate this effect.It expects that each of the InputExamples consists of a pair of texts and a float valued label, representing the expected similarity score between the pair.
It computes the following loss function:
loss = logsum(1+exp(s(k,l)-s(i,j))+exp...), where(i,j)and(k,l)are any of the input pairs in the batch such that the expected similarity of(i,j)is greater than(k,l). The summation is over all possible pairs of input pairs in the batch that match this condition. This is the same as CoSENTLoss, with a different similarity function.- Parameters
model – SentenceTransformerModel
scale – Output of similarity function is multiplied by scale value. Represents the inverse temperature.
- References:
For further details, see: https://arxiv.org/abs/2309.12871v1
- Requirements:
Sentence pairs with corresponding similarity scores in range of the similarity function. Default is [-1,1].
- Relations:
CoSENTLossis AnglELoss withpairwise_cos_simas the metric, rather thanpairwise_angle_sim.CosineSimilarityLossseems to produce a weaker training signal thanCoSENTLossorAnglELoss.
- Inputs:
Texts
Labels
(sentence_A, sentence_B) pairs
float similarity score
- Example:
from sentence_transformers import SentenceTransformer, losses from sentence_transformers.readers import InputExample model = SentenceTransformer('bert-base-uncased') train_examples = [InputExample(texts=['My first sentence', 'My second sentence'], label=1.0), InputExample(texts=['My third sentence', 'Unrelated sentence'], label=0.3)] train_dataloader = DataLoader(train_examples, shuffle=True, batch_size=train_batch_size) train_loss = losses.AnglELoss(model=model)
CosineSimilarityLoss¶
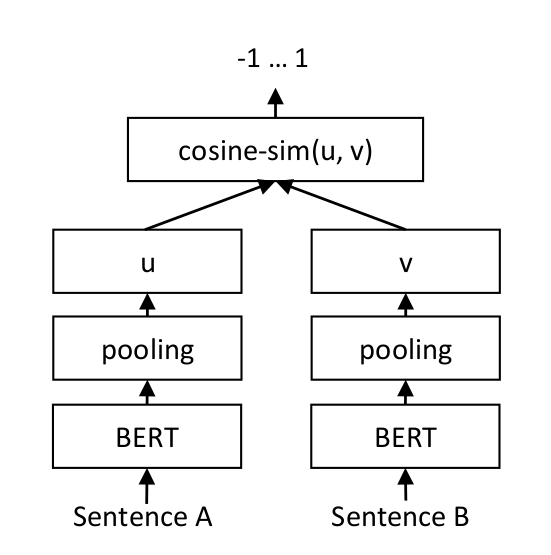
For each sentence pair, we pass sentence A and sentence B through our network which yields the embeddings u und v. The similarity of these embeddings is computed using cosine similarity and the result is compared to the gold similarity score.
This allows our network to be fine-tuned to recognize the similarity of sentences.
-
class
sentence_transformers.losses.CosineSimilarityLoss(model: sentence_transformers.SentenceTransformer.SentenceTransformer, loss_fct=MSELoss(), cos_score_transformation=Identity())¶ CosineSimilarityLoss expects that the InputExamples consists of two texts and a float label. It computes the vectors
u = model(sentence_A)andv = model(sentence_B)and measures the cosine-similarity between the two. By default, it minimizes the following loss:||input_label - cos_score_transformation(cosine_sim(u,v))||_2.- Parameters
model – SentenceTransformer model
loss_fct – Which pytorch loss function should be used to compare the
cosine_similarity(u, v)with the input_label? By default, MSE is used:||input_label - cosine_sim(u, v)||_2cos_score_transformation – The cos_score_transformation function is applied on top of cosine_similarity. By default, the identify function is used (i.e. no change).
- References:
- Requirements:
Sentence pairs with corresponding similarity scores in range [0, 1]
- Relations:
CoSENTLossseems to produce a stronger training signal than CosineSimilarityLoss. In our experiments, CoSENTLoss is recommended.AnglELossisCoSENTLosswithpairwise_angle_simas the metric, rather thanpairwise_cos_sim. It also produces a stronger training signal than CosineSimilarityLoss.
- Inputs:
Texts
Labels
(sentence_A, sentence_B) pairs
float similarity score
- Example:
from sentence_transformers import SentenceTransformer, InputExample, losses from torch.utils.data import DataLoader model = SentenceTransformer('distilbert-base-nli-mean-tokens') train_examples = [ InputExample(texts=['My first sentence', 'My second sentence'], label=0.8), InputExample(texts=['Another pair', 'Unrelated sentence'], label=0.3) ] train_batch_size = 1 train_dataloader = DataLoader(train_examples, shuffle=True, batch_size=train_batch_size) train_loss = losses.CosineSimilarityLoss(model=model) model.fit( [(train_dataloader, train_loss)], epochs=10, )
DenoisingAutoEncoderLoss¶
-
class
sentence_transformers.losses.DenoisingAutoEncoderLoss(model: sentence_transformers.SentenceTransformer.SentenceTransformer, decoder_name_or_path: Optional[str] = None, tie_encoder_decoder: bool = True)¶ This loss expects as input a pairs of damaged sentences and the corresponding original ones. During training, the decoder reconstructs the original sentences from the encoded sentence embeddings. Here the argument ‘decoder_name_or_path’ indicates the pretrained model (supported by Hugging Face) to be used as the decoder. Since decoding process is included, here the decoder should have a class called XXXLMHead (in the context of Hugging Face’s Transformers). The ‘tie_encoder_decoder’ flag indicates whether to tie the trainable parameters of encoder and decoder, which is shown beneficial to model performance while limiting the amount of required memory. Only when the encoder and decoder are from the same architecture, can the flag ‘tie_encoder_decoder’ work.
The data generation process (i.e. the ‘damaging’ process) has already been implemented in
DenoisingAutoEncoderDataset, allowing you to only provide regular sentences.- Parameters
model – SentenceTransformer model
decoder_name_or_path – Model name or path for initializing a decoder (compatible with Huggingface’s Transformers)
tie_encoder_decoder – whether to tie the trainable parameters of encoder and decoder
- References:
- Requirements:
The decoder should have a class called XXXLMHead (in the context of Hugging Face’s Transformers)
Should use a large corpus
- Inputs:
Texts
Labels
(damaged_sentence, original_sentence) pairs
none
sentence fed through
DenoisingAutoEncoderDatasetnone
- Example:
from sentence_transformers import SentenceTransformer, losses from sentence_transformers.datasets import DenoisingAutoEncoderDataset from torch.utils.data import DataLoader model_name = "bert-base-cased" model = SentenceTransformer(model_name) train_sentences = [ "First training sentence", "Second training sentence", "Third training sentence", "Fourth training sentence", ] batch_size = 2 train_dataset = DenoisingAutoEncoderDataset(train_sentences) train_dataloader = DataLoader(train_dataset, batch_size=batch_size, shuffle=True, drop_last=True) train_loss = losses.DenoisingAutoEncoderLoss( model, decoder_name_or_path=model_name, tie_encoder_decoder=True ) model.fit( train_objectives=[(train_dataloader, train_loss)], epochs=10, )
GISTEmbedLoss¶
-
class
sentence_transformers.losses.GISTEmbedLoss(model: sentence_transformers.SentenceTransformer.SentenceTransformer, guide: sentence_transformers.SentenceTransformer.SentenceTransformer, temperature: float = 0.01)¶ This loss is used to train a SentenceTransformer model using the GISTEmbed algorithm. It takes a model and a guide model as input, and uses the guide model to guide the in-batch negative sample selection. The cosine similarity is used to compute the loss and the temperature parameter is used to scale the cosine similarities.
- Parameters
model – SentenceTransformer model based on a transformers model.
guide – SentenceTransformer model to guide the in-batch negative sample selection.
temperature – Temperature parameter to scale the cosine similarities.
- References:
For further details, see: https://arxiv.org/abs/2402.16829
- Requirements:
(anchor, positive, negative) triplets
(anchor, positive) pairs
- Relations:
MultipleNegativesRankingLossis similar to this loss, but it does not use a guide model to guide the in-batch negative sample selection. GISTEmbedLoss yields a stronger training signal at the cost of some training overhead.
- Inputs:
Texts
Labels
(anchor, positive, negative) triplets
none
(anchor, positive) pairs
none
- Example:
from sentence_transformers import SentenceTransformer, losses, InputExample from torch.utils.data import DataLoader model = SentenceTransformer('all-MiniLM-L6-v2') guide = SentenceTransformer('avsolatorio/GIST-small-Embedding-v0') train_examples = [ InputExample(texts=['The first query', 'The first positive passage', 'The first negative passage']), InputExample(texts=['The second query', 'The second positive passage', 'The second negative passage']), ] train_dataloader = DataLoader(train_examples, shuffle=True, batch_size=2) train_loss = losses.GISTEmbedLoss(model=model, guide=guide) model.fit( [(train_dataloader, train_loss)], epochs=10, )
CachedGISTEmbedLoss¶
-
class
sentence_transformers.losses.CachedGISTEmbedLoss(model: sentence_transformers.SentenceTransformer.SentenceTransformer, guide: sentence_transformers.SentenceTransformer.SentenceTransformer, temperature: float = 0.01, mini_batch_size: int = 32, show_progress_bar: bool = False)¶ This loss is a combination of
GISTEmbedLossandCachedMultipleNegativesRankingLoss. Typically,MultipleNegativesRankingLossrequires a larger batch size for better performance.GISTEmbedLossyields stronger training signals thanMultipleNegativesRankingLossdue to the use of a guide model for in-batch negative sample selection. Meanwhile,CachedMultipleNegativesRankingLossallows for scaling of the batch size by dividing the computation into two stages of embedding and loss calculation, which both can be scaled by mini-batches (https://arxiv.org/pdf/2101.06983.pdf).By combining the guided selection from
GISTEmbedLossand Gradient Cache fromCachedMultipleNegativesRankingLoss, it is possible to reduce memory usage while maintaining performance levels comparable to those ofGISTEmbedLoss.- Parameters
model – SentenceTransformer model
guide – SentenceTransformer model to guide the in-batch negative sample selection.
temperature – Temperature parameter to scale the cosine similarities.
- References:
Efficient Natural Language Response Suggestion for Smart Reply, Section 4.4: https://arxiv.org/pdf/1705.00652.pdf
Scaling Deep Contrastive Learning Batch Size under Memory Limited Setup: https://arxiv.org/pdf/2101.06983.pdf
GISTEmbed: Guided In-sample Selection of Training Negatives for Text Embedding Fine-tuning https://arxiv.org/abs/2402.16829
- Requirements:
(anchor, positive) pairs or (anchor, positive, negative pairs)
Should be used with large batch sizes for superior performance, but has slower training time than
MultipleNegativesRankingLoss
- Relations:
Equivalent to
GISTEmbedLoss, but with caching that allows for much higher batch sizes
- Inputs:
Texts
Labels
(anchor, positive) pairs
none
(anchor, positive, negative) triplets
none
- Example:
from sentence_transformers import SentenceTransformer, losses, InputExample from torch.utils.data import DataLoader model = SentenceTransformer('distilbert-base-uncased') guide = SentenceTransformer('avsolatorio/GIST-small-Embedding-v0') train_examples = [ InputExample(texts=['Anchor 1', 'Positive 1']), InputExample(texts=['Anchor 2', 'Positive 2']), ] train_dataloader = DataLoader(train_examples, shuffle=True, batch_size=1024) # Here we can try much larger batch sizes! train_loss = losses.CachedGISTEmbedLoss(model=model, mini_batch_size=32, guide=guide) model.fit( [(train_dataloader, train_loss)], epochs=10, )
MSELoss¶
-
class
sentence_transformers.losses.MSELoss(model)¶ Computes the MSE loss between the computed sentence embedding and a target sentence embedding. This loss is used when extending sentence embeddings to new languages as described in our publication Making Monolingual Sentence Embeddings Multilingual using Knowledge Distillation.
For an example, see the distillation documentation on extending language models to new languages.
- Parameters
model – SentenceTransformerModel
- References:
Making Monolingual Sentence Embeddings Multilingual using Knowledge Distillation: https://arxiv.org/abs/2004.09813
- Requirements:
Usually uses a finetuned teacher M in a knowledge distillation setup
- Relations:
MarginMSELossis equivalent to this loss, but with a margin through a negative pair.
- Input:
Texts
Labels
single sentences
model sentence embeddings
Example:
from sentence_transformers import SentenceTransformer, InputExample, losses from torch.utils.data import DataLoader model_en = SentenceTransformer('bert-base-cased') model_fr = SentenceTransformer('flaubert/flaubert_base_cased') examples_en = ['The first sentence', 'The second sentence', 'The third sentence', 'The fourth sentence'] examples_fr = ['La première phrase', 'La deuxième phrase', 'La troisième phrase', 'La quatrième phrase'] train_batch_size = 2 labels_en_en = model_en.encode(examples_en) examples_en_fr = [InputExample(texts=[x], label=labels_en_en[i]) for i, x in enumerate(examples_en)] loader_en_fr = DataLoader(examples_en_fr, batch_size=train_batch_size) examples_fr_fr = [InputExample(texts=[x], label=labels_en_en[i]) for i, x in enumerate(examples_fr)] loader_fr_fr = DataLoader(examples_fr_fr, batch_size=train_batch_size) train_loss = losses.MSELoss(model=model_fr) model_fr.fit( [(loader_en_fr, train_loss), (loader_fr_fr, train_loss)], epochs=10, )
MarginMSELoss¶
-
class
sentence_transformers.losses.MarginMSELoss(model, similarity_fct=<function pairwise_dot_score>)¶ Compute the MSE loss between the
|sim(Query, Pos) - sim(Query, Neg)|and|gold_sim(Query, Pos) - gold_sim(Query, Neg)|. By default, sim() is the dot-product. The gold_sim is often the similarity score from a teacher model.In contrast to
MultipleNegativesRankingLoss, the two passages do not have to be strictly positive and negative, both can be relevant or not relevant for a given query. This can be an advantage of MarginMSELoss over MultipleNegativesRankingLoss, but note that the MarginMSELoss is much slower to train. With MultipleNegativesRankingLoss, with a batch size of 64, we compare one query against 128 passages. With MarginMSELoss, we compare a query only against two passages.- Parameters
model – SentenceTransformerModel
similarity_fct – Which similarity function to use.
- References:
For more details, please refer to https://arxiv.org/abs/2010.02666.
- Requirements:
(query, passage_one, passage_two) triplets
Usually used with a finetuned teacher M in a knowledge distillation setup
- Relations:
MSELossis equivalent to this loss, but without a margin through the negative pair.
- Inputs:
Texts
Labels
(query, passage_one, passage_two) triplets
M(query, passage_one) - M(query, passage_two)
- Example:
from sentence_transformers import SentenceTransformer, InputExample, losses from sentence_transformers.util import pairwise_dot_score from torch.utils.data import DataLoader import torch student_model = SentenceTransformer('sentence-transformers/distilbert-base-nli-mean-tokens') teacher_model = SentenceTransformer('sentence-transformers/bert-base-nli-stsb-mean-tokens') train_examples = [ ['The first query', 'The first positive passage', 'The first negative passage'], ['The second query', 'The second positive passage', 'The second negative passage'], ['The third query', 'The third positive passage', 'The third negative passage'], ] train_batch_size = 1 encoded = torch.tensor([teacher_model.encode(x).tolist() for x in train_examples]) labels = pairwise_dot_score(encoded[:, 0], encoded[:, 1]) - pairwise_dot_score(encoded[:, 0], encoded[:, 2]) train_input_examples = [InputExample(texts=x, label=labels[i]) for i, x in enumerate(train_examples)] train_dataloader = DataLoader(train_input_examples, shuffle=True, batch_size=train_batch_size) train_loss = losses.MarginMSELoss(model=student_model) student_model.fit( [(train_dataloader, train_loss)], epochs=10, )
MatryoshkaLoss¶
-
class
sentence_transformers.losses.MatryoshkaLoss(model: sentence_transformers.SentenceTransformer.SentenceTransformer, loss: torch.nn.modules.module.Module, matryoshka_dims: List[int], matryoshka_weights: Optional[List[Union[float, int]]] = None, n_dims_per_step: int = - 1)¶ The MatryoshkaLoss can be seen as a loss modifier that allows you to use other loss functions at various different embedding dimensions. This is useful for when you want to train a model where users have the option to lower the embedding dimension to improve their embedding comparison speed and costs.
- Parameters
model – SentenceTransformer model
loss – The loss function to be used, e.g.
MultipleNegativesRankingLoss,CoSENTLoss, etc.matryoshka_dims – A list of embedding dimensions to be used for the loss function, e.g. [768, 512, 256, 128, 64].
matryoshka_weights – A list of weights to be used for the loss function, e.g. [1, 1, 1, 1, 1]. If None, then the weights will be set to 1 for all dimensions.
n_dims_per_step – The number of dimensions to use per step. If -1, then all dimensions are used. If > 0, then a random sample of n_dims_per_step dimensions are used per step. The default value is -1.
- References:
The concept was introduced in this paper: https://arxiv.org/abs/2205.13147
- Requirements:
The base loss cannot be
CachedMultipleNegativesRankingLoss.
- Relations:
Matryoshka2dLossuses this loss in combination withAdaptiveLayerLosswhich allows forlayer reduction for faster inference.
- Input:
Texts
Labels
any
any
- Example:
from sentence_transformers import SentenceTransformer, losses, InputExample from torch.utils.data import DataLoader model = SentenceTransformer('microsoft/mpnet-base') train_examples = [ InputExample(texts=['Anchor 1', 'Positive 1']), InputExample(texts=['Anchor 2', 'Positive 2']), ] train_dataloader = DataLoader(train_examples, shuffle=True, batch_size=32) train_loss = losses.MultipleNegativesRankingLoss(model=model) train_loss = losses.MatryoshkaLoss(model, train_loss, [768, 512, 256, 128, 64]) model.fit( [(train_dataloader, train_loss)], epochs=10, )
Matryoshka2dLoss¶
-
class
sentence_transformers.losses.Matryoshka2dLoss(model: sentence_transformers.SentenceTransformer.SentenceTransformer, loss: torch.nn.modules.module.Module, matryoshka_dims: List[int], matryoshka_weights: Optional[List[Union[float, int]]] = None, n_layers_per_step: int = 1, n_dims_per_step: int = 1, last_layer_weight: float = 1.0, prior_layers_weight: float = 1.0, kl_div_weight: float = 1.0, kl_temperature: float = 0.3)¶ The Matryoshka2dLoss can be seen as a loss modifier that combines the
AdaptiveLayerLossand theMatryoshkaLoss. This allows you to train an embedding model that 1) allows users to specify the number of model layers to use, and 2) allows users to specify the output dimensions to use.The former is useful for when you want users to have the option to lower the number of layers used to improve their inference speed and memory usage, and the latter is useful for when you want users to have the option to lower the output dimensions to improve the efficiency of their downstream tasks (e.g. retrieval) or to lower their storage costs.
Note, this uses n_layers_per_step=1 and n_dims_per_step=1 as default, following the original 2DMSE implementation.
- Parameters
model – SentenceTransformer model
loss – The loss function to be used, e.g.
MultipleNegativesRankingLoss,CoSENTLoss, etc.matryoshka_dims – A list of embedding dimensions to be used for the loss function, e.g. [768, 512, 256, 128, 64].
matryoshka_weights – A list of weights to be used for the loss function, e.g. [1, 1, 1, 1, 1]. If None, then the weights will be set to 1 for all dimensions.
n_layers_per_step – The number of layers to use per step. If -1, then all layers are used. If > 0, then a random sample of n_layers_per_step layers are used per step. The 2DMSE paper uses n_layers_per_step=1. The default value is -1.
n_dims_per_step – The number of dimensions to use per step. If -1, then all dimensions are used. If > 0, then a random sample of n_dims_per_step dimensions are used per step. The default value is -1.
last_layer_weight – The weight to use for the loss of the final layer. Increase this to focus more on the performance when using all layers. The default value is 1.0.
prior_layers_weight – The weight to use for the loss of the prior layers. Increase this to focus more on the performance when using fewer layers. The default value is 1.0.
kl_div_weight – The weight to use for the KL-divergence loss that is used to make the prior layers match that of the last layer. Increase this to focus more on the performance when using fewer layers. The default value is 1.0.
kl_temperature – The temperature to use for the KL-divergence loss. If 0, then the KL-divergence loss is not used. The default value is 1.0.
- References:
See the 2D Matryoshka Sentence Embeddings (2DMSE) paper: https://arxiv.org/abs/2402.14776
- Requirements:
The base loss cannot be
CachedMultipleNegativesRankingLoss.
- Relations:
MatryoshkaLossis used in this loss, and it is responsible for the dimensionality reduction.AdaptiveLayerLossis used in this loss, and it is responsible for the layer reduction.
- Input:
Texts
Labels
any
any
- Example:
from sentence_transformers import SentenceTransformer, losses, InputExample from torch.utils.data import DataLoader model = SentenceTransformer('microsoft/mpnet-base') train_examples = [ InputExample(texts=['Anchor 1', 'Positive 1']), InputExample(texts=['Anchor 2', 'Positive 2']), ] train_dataloader = DataLoader(train_examples, shuffle=True, batch_size=32) train_loss = losses.MultipleNegativesRankingLoss(model=model) train_loss = losses.Matryoshka2dLoss(model, train_loss, [768, 512, 256, 128, 64]) model.fit( [(train_dataloader, train_loss)], epochs=10, )
AdaptiveLayerLoss¶
-
class
sentence_transformers.losses.AdaptiveLayerLoss(model: sentence_transformers.SentenceTransformer.SentenceTransformer, loss: torch.nn.modules.module.Module, n_layers_per_step: int = 1, last_layer_weight: float = 1.0, prior_layers_weight: float = 1.0, kl_div_weight: float = 1.0, kl_temperature: float = 0.3)¶ The AdaptiveLayerLoss can be seen as a loss modifier that allows you to use other loss functions at non-final layers of the Sentence Transformer model. This is useful for when you want to train a model where users have the option to lower the number of layers used to improve their inference speed and memory usage.
- Parameters
model – SentenceTransformer model
loss – The loss function to be used, e.g.
MultipleNegativesRankingLoss,CoSENTLoss, etc.n_layers_per_step – The number of layers to use per step. If -1, then all layers are used. If > 0, then a random sample of n_layers_per_step layers are used per step, separate from the final layer, which is always used. The 2DMSE paper uses n_layers_per_step=1. The default value is 1.
last_layer_weight – The weight to use for the loss of the final layer. Increase this to focus more on the performance when using all layers. The default value is 1.0.
prior_layers_weight – The weight to use for the loss of the prior layers. Increase this to focus more on the performance when using fewer layers. The default value is 1.0.
kl_div_weight – The weight to use for the KL-divergence loss that is used to make the prior layers match that of the last layer. Increase this to focus more on the performance when using fewer layers. The default value is 1.0.
kl_temperature – The temperature to use for the KL-divergence loss. If 0, then the KL-divergence loss is not used. The default value is 1.0.
- References:
The concept was inspired by the 2DMSE paper: https://arxiv.org/abs/2402.14776
- Requirements:
The base loss cannot be
CachedMultipleNegativesRankingLoss.
- Relations:
Matryoshka2dLossuses this loss in combination withMatryoshkaLosswhich allows foroutput dimensionality reduction for faster downstream tasks (e.g. retrieval).
- Input:
Texts
Labels
any
any
- Example:
from sentence_transformers import SentenceTransformer, losses, InputExample from torch.utils.data import DataLoader model = SentenceTransformer('microsoft/mpnet-base') train_examples = [ InputExample(texts=['Anchor 1', 'Positive 1']), InputExample(texts=['Anchor 2', 'Positive 2']), ] train_dataloader = DataLoader(train_examples, shuffle=True, batch_size=32) train_loss = losses.MultipleNegativesRankingLoss(model=model) train_loss = losses.AdaptiveLayerLoss(model, train_loss) model.fit( [(train_dataloader, train_loss)], epochs=10, )
MegaBatchMarginLoss¶
-
class
sentence_transformers.losses.MegaBatchMarginLoss(model, positive_margin: float = 0.8, negative_margin: float = 0.3, use_mini_batched_version: bool = True, mini_batch_size: int = 50)¶ Given a large batch (like 500 or more examples) of (anchor_i, positive_i) pairs, find for each pair in the batch the hardest negative, i.e. find j != i such that cos_sim(anchor_i, positive_j) is maximal. Then create from this a triplet (anchor_i, positive_i, positive_j) where positive_j serves as the negative for this triplet.
Then train as with the triplet loss.
- Parameters
model – SentenceTransformerModel
positive_margin – Positive margin, cos(anchor, positive) should be > positive_margin
negative_margin – Negative margin, cos(anchor, negative) should be < negative_margin
use_mini_batched_version – As large batch sizes require a lot of memory, we can use a mini-batched version. We break down the large batch into smaller batches with fewer examples.
mini_batch_size – Size for the mini-batches. Should be a devisor for the batch size in your data loader.
- References:
This loss function was inspired by the ParaNMT paper: https://www.aclweb.org/anthology/P18-1042/
- Requirements:
(anchor, positive) pairs
Large batches (500 or more examples)
- Input:
Texts
Labels
(anchor, positive) pairs
none
- Example:
from sentence_transformers import SentenceTransformer, InputExample, losses from torch.utils.data import DataLoader model = SentenceTransformer('all-MiniLM-L6-v2') total_examples = 500 train_batch_size = 250 train_mini_batch_size = 32 train_examples = [ InputExample(texts=[f"This is sentence number {i}", f"This is sentence number {i+1}"]) for i in range(total_examples) ] train_dataloader = DataLoader(train_examples, shuffle=True, batch_size=train_batch_size) train_loss = losses.MegaBatchMarginLoss(model=model, mini_batch_size=train_mini_batch_size) model.fit( [(train_dataloader, train_loss)], epochs=10, )
MultipleNegativesRankingLoss¶
MultipleNegativesRankingLoss is a great loss function if you only have positive pairs, for example, only pairs of similar texts like pairs of paraphrases, pairs of duplicate questions, pairs of (query, response), or pairs of (source_language, target_language).
-
class
sentence_transformers.losses.MultipleNegativesRankingLoss(model: sentence_transformers.SentenceTransformer.SentenceTransformer, scale: float = 20.0, similarity_fct=<function cos_sim>)¶ This loss expects as input a batch consisting of sentence pairs
(a_1, p_1), (a_2, p_2)..., (a_n, p_n)where we assume that(a_i, p_i)are a positive pair and(a_i, p_j)fori != ja negative pair.For each
a_i, it uses all otherp_jas negative samples, i.e., fora_i, we have 1 positive example (p_i) andn-1negative examples (p_j). It then minimizes the negative log-likehood for softmax normalized scores.This loss function works great to train embeddings for retrieval setups where you have positive pairs (e.g. (query, relevant_doc)) as it will sample in each batch
n-1negative docs randomly.The performance usually increases with increasing batch sizes.
You can also provide one or multiple hard negatives per anchor-positive pair by structering the data like this:
(a_1, p_1, n_1), (a_2, p_2, n_2). Then,n_1is a hard negative for(a_1, p_1). The loss will use for the pair(a_i, p_i)allp_jforj != iand alln_jas negatives.- Parameters
model – SentenceTransformer model
scale – Output of similarity function is multiplied by scale value
similarity_fct – similarity function between sentence embeddings. By default, cos_sim. Can also be set to dot product (and then set scale to 1)
- References:
Efficient Natural Language Response Suggestion for Smart Reply, Section 4.4: https://arxiv.org/pdf/1705.00652.pdf
- Requirements:
(anchor, positive) pairs or (anchor, positive, negative) triplets
- Relations:
CachedMultipleNegativesRankingLossis equivalent to this loss, but it uses caching that allows for much higher batch sizes (and thus better performance) without extra memory usage. However, it requires more training time.MultipleNegativesSymmetricRankingLossis equivalent to this loss, but with an additional loss term.GISTEmbedLossis equivalent to this loss, but uses a guide model to guide the in-batch negative sample selection. GISTEmbedLoss yields a stronger training signal at the cost of some training overhead.
- Inputs:
Texts
Labels
(anchor, positive) pairs
none
(anchor, positive, negative) triplets
none
- Example:
from sentence_transformers import SentenceTransformer, losses, InputExample from torch.utils.data import DataLoader model = SentenceTransformer('distilbert-base-uncased') train_examples = [ InputExample(texts=['Anchor 1', 'Positive 1']), InputExample(texts=['Anchor 2', 'Positive 2']), ] train_dataloader = DataLoader(train_examples, shuffle=True, batch_size=32) train_loss = losses.MultipleNegativesRankingLoss(model=model) model.fit( [(train_dataloader, train_loss)], epochs=10, )
CachedMultipleNegativesRankingLoss¶
-
class
sentence_transformers.losses.CachedMultipleNegativesRankingLoss(model: SentenceTransformer, scale: float = 20.0, similarity_fct: callable[[Tensor, Tensor], Tensor] = <function cos_sim>, mini_batch_size: int = 32, show_progress_bar: bool = False)¶ Boosted version of MultipleNegativesRankingLoss (https://arxiv.org/pdf/1705.00652.pdf) by GradCache (https://arxiv.org/pdf/2101.06983.pdf).
Constrastive learning (here our MNRL loss) with in-batch negatives is usually hard to work with large batch sizes due to (GPU) memory limitation. Even with batch-scaling methods like gradient-scaling, it cannot work either. This is because the in-batch negatives make the data points within the same batch non-independent and thus the batch cannot be broke down into mini-batches. GradCache is a smart way to solve this problem. It achieves the goal by dividing the computation into two stages of embedding and loss calculation, which both can be scaled by mini-batches. As a result, memory of constant size (e.g. that works with batch size = 32) can now process much larger batches (e.g. 65536).
In detail:
It first does a quick embedding step without gradients/computation graphs to get all the embeddings;
Calculate the loss, backward up to the embeddings and cache the gradients wrt. to the embeddings;
A 2nd embedding step with gradients/computation graphs and connect the cached gradients into the backward chain.
Notes: All steps are done with mini-batches. In the original implementation of GradCache, (2) is not done in mini-batches and requires a lot memory when batch size large. One drawback is about the speed. GradCache will sacrifice around 20% computation time according to the paper.
- Parameters
model – SentenceTransformer model
scale – Output of similarity function is multiplied by scale value
similarity_fct – similarity function between sentence embeddings. By default, cos_sim. Can also be set to dot product (and then set scale to 1)
- References:
Efficient Natural Language Response Suggestion for Smart Reply, Section 4.4: https://arxiv.org/pdf/1705.00652.pdf
Scaling Deep Contrastive Learning Batch Size under Memory Limited Setup: https://arxiv.org/pdf/2101.06983.pdf
- Requirements:
(anchor, positive) pairs or (anchor, positive, negative pairs)
Should be used with large batch sizes for superior performance, but has slower training time than
MultipleNegativesRankingLoss
- Relations:
Equivalent to
MultipleNegativesRankingLoss, but with caching that allows for much higher batch sizes
(and thus better performance) without extra memory usage. This loss also trains roughly 2x to 2.4x slower than
MultipleNegativesRankingLoss.- Inputs:
Texts
Labels
(anchor, positive) pairs
none
(anchor, positive, negative) triplets
none
- Example:
from sentence_transformers import SentenceTransformer, losses, InputExample from torch.utils.data import DataLoader model = SentenceTransformer('distilbert-base-uncased') train_examples = [ InputExample(texts=['Anchor 1', 'Positive 1']), InputExample(texts=['Anchor 2', 'Positive 2']), ] train_dataloader = DataLoader(train_examples, shuffle=True, batch_size=1024) # Here we can try much larger batch sizes! train_loss = losses.CachedMultipleNegativesRankingLoss(model=model, mini_batch_size = 32) model.fit( [(train_dataloader, train_loss)], epochs=10, )
MultipleNegativesSymmetricRankingLoss¶
-
class
sentence_transformers.losses.MultipleNegativesSymmetricRankingLoss(model: sentence_transformers.SentenceTransformer.SentenceTransformer, scale: float = 20.0, similarity_fct=<function cos_sim>)¶ This loss is an adaptation of MultipleNegativesRankingLoss. MultipleNegativesRankingLoss computes the following loss: For a given anchor and a list of candidates, find the positive candidate.
In MultipleNegativesSymmetricRankingLoss, we add another loss term: Given the positive and a list of all anchors, find the correct (matching) anchor.
For the example of question-answering: You have (question, answer)-pairs. MultipleNegativesRankingLoss just computes the loss to find the answer for a given question. MultipleNegativesSymmetricRankingLoss additionally computes the loss to find the question for a given answer.
Note: If you pass triplets, the negative entry will be ignored. A anchor is just searched for the positive.
- Parameters
model – SentenceTransformer model
scale – Output of similarity function is multiplied by scale value
similarity_fct – similarity function between sentence embeddings. By default, cos_sim. Can also be set to dot product (and then set scale to 1)
- Requirements:
(anchor, positive) pairs
- Relations:
Like
MultipleNegativesRankingLoss, but with an additional loss term.
- Inputs:
Texts
Labels
(anchor, positive) pairs
none
- Example:
from sentence_transformers import SentenceTransformer, losses, InputExample from torch.utils.data import DataLoader model = SentenceTransformer('distilbert-base-uncased') train_examples = [ InputExample(texts=['Anchor 1', 'Positive 1']), InputExample(texts=['Anchor 2', 'Positive 2']), ] train_dataloader = DataLoader(train_examples, shuffle=True, batch_size=32) train_loss = losses.MultipleNegativesSymmetricRankingLoss(model=model) model.fit( [(train_dataloader, train_loss)], epochs=10, )
SoftmaxLoss¶
-
class
sentence_transformers.losses.SoftmaxLoss(model: sentence_transformers.SentenceTransformer.SentenceTransformer, sentence_embedding_dimension: int, num_labels: int, concatenation_sent_rep: bool = True, concatenation_sent_difference: bool = True, concatenation_sent_multiplication: bool = False, loss_fct: Callable = CrossEntropyLoss())¶ This loss was used in our SBERT publication (https://arxiv.org/abs/1908.10084) to train the SentenceTransformer model on NLI data. It adds a softmax classifier on top of the output of two transformer networks.
MultipleNegativesRankingLossis an alternative loss function that often yields better results, as per https://arxiv.org/abs/2004.09813.- Parameters
model – SentenceTransformer model
sentence_embedding_dimension – Dimension of your sentence embeddings
num_labels – Number of different labels
concatenation_sent_rep – Concatenate vectors u,v for the softmax classifier?
concatenation_sent_difference – Add abs(u-v) for the softmax classifier?
concatenation_sent_multiplication – Add u*v for the softmax classifier?
loss_fct – Optional: Custom pytorch loss function. If not set, uses nn.CrossEntropyLoss()
- References:
Sentence-BERT: Sentence Embeddings using Siamese BERT-Networks: https://arxiv.org/abs/1908.10084
- Requirements:
sentence pairs with a class label
- Inputs:
Texts
Labels
(sentence_A, sentence_B) pairs
class
- Example:
from sentence_transformers import SentenceTransformer, SentencesDataset, losses from sentence_transformers.readers import InputExample from torch.utils.data import DataLoader model = SentenceTransformer('distilbert-base-nli-mean-tokens') train_examples = [ InputExample(texts=['First pair, sent A', 'First pair, sent B'], label=0), InputExample(texts=['Second pair, sent A', 'Second pair, sent B'], label=1), InputExample(texts=['Third pair, sent A', 'Third pair, sent B'], label=0), InputExample(texts=['Fourth pair, sent A', 'Fourth pair, sent B'], label=2), ] train_batch_size = 2 train_dataset = SentencesDataset(train_examples, model) train_dataloader = DataLoader(train_dataset, shuffle=True, batch_size=train_batch_size) train_loss = losses.SoftmaxLoss( model=model, sentence_embedding_dimension=model.get_sentence_embedding_dimension(), num_labels=len(set(x.label for x in train_examples)) ) model.fit( [(train_dataloader, train_loss)], epochs=10, )
TripletLoss¶
-
class
sentence_transformers.losses.TripletLoss(model: sentence_transformers.SentenceTransformer.SentenceTransformer, distance_metric=<function TripletDistanceMetric.<lambda>>, triplet_margin: float = 5)¶ This class implements triplet loss. Given a triplet of (anchor, positive, negative), the loss minimizes the distance between anchor and positive while it maximizes the distance between anchor and negative. It compute the following loss function:
loss = max(||anchor - positive|| - ||anchor - negative|| + margin, 0).Margin is an important hyperparameter and needs to be tuned respectively.
- Parameters
model – SentenceTransformerModel
distance_metric – Function to compute distance between two embeddings. The class TripletDistanceMetric contains common distance metrices that can be used.
triplet_margin – The negative should be at least this much further away from the anchor than the positive.
- References:
For further details, see: https://en.wikipedia.org/wiki/Triplet_loss
- Requirements:
(anchor, positive, negative) triplets
- Inputs:
Texts
Labels
(anchor, positive, negative) triplets
none
- Example:
from sentence_transformers import SentenceTransformer, SentencesDataset, losses from sentence_transformers.readers import InputExample from torch.utils.data import DataLoader model = SentenceTransformer('distilbert-base-nli-mean-tokens') train_examples = [ InputExample(texts=['Anchor 1', 'Positive 1', 'Negative 1']), InputExample(texts=['Anchor 2', 'Positive 2', 'Negative 2']), ] train_batch_size = 1 train_dataset = SentencesDataset(train_examples, model) train_dataloader = DataLoader(train_dataset, shuffle=True, batch_size=train_batch_size) train_loss = losses.TripletLoss(model=model) model.fit( [(train_dataloader, train_loss)], epochs=10, )