Domain Adaptation
The goal of Domain Adaptation is to adapt text embedding models to your specific text domain without the need to have labeled training data.
Domain adaptation is still an active research field and there exists no perfect solution yet. However, in our two recent papers TSDAE and GPL we evaluated several methods how text embeddings model can be adapted to your specific domain. You can find an overview of these methods in my talk on unsupervised domain adaptation.
Domain Adaptation vs. Unsupervised Learning
There exists methods for unsupervised text embedding learning, however, they generally perform rather badly: They are not really able to learn domain specific concepts.
A much better approach is domain adaptation: Here you have an unlabeled corpus from your specific domain together with an existing labeled corpus. You can find many suitable labeled training datasets here: Embedding Model Datasets Collection
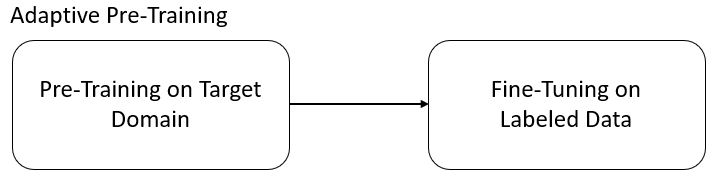
Adaptive Pre-Training
When using adaptive pre-training, you first pre-train on your target corpus using e.g. Masked Language Modeling or TSDAE and then you fine-tune on an existing training dataset (see Embedding Model Datasets Collection).
In our paper TSDAE we evaluated several methods for domain adaptation on 4 domain specific sentence embedding tasks:
| Approach | AskUbuntu | CQADupStack | SciDocs | Avg | |
|---|---|---|---|---|---|
| Zero-Shot Model | 54.5 | 12.9 | 72.2 | 69.4 | 52.3 |
| TSDAE | 59.4 | 14.4 | 74.5 | 77.6 | 56.5 |
| MLM | 60.6 | 14.3 | 71.8 | 76.9 | 55.9 |
| CT | 56.4 | 13.4 | 72.4 | 69.7 | 53.0 |
| SimCSE | 56.2 | 13.1 | 71.4 | 68.9 | 52.4 |
As we can see, the performance can improve up-to 8 points when you first perform pre-training on your specific corpus and then fine-tune on provided labeled training data.
In GPL we evaluate these methods for semantic search: Given a short query, find the relevant passage. Here, performance can improve up to 10 points:
| Approach | FiQA | SciFact | BioASQ | TREC-COVID | CQADupStack | Robust04 | Avg |
|---|---|---|---|---|---|---|---|
| Zero-Shot Model | 26.7 | 57.1 | 52.9 | 66.1 | 29.6 | 39.0 | 45.2 |
| TSDAE | 29.3 | 62.8 | 55.5 | 76.1 | 31.8 | 39.4 | 49.2 |
| MLM | 30.2 | 60.0 | 51.3 | 69.5 | 30.4 | 38.8 | 46.7 |
| ICT | 27.0 | 58.3 | 55.3 | 69.7 | 31.3 | 37.4 | 46.5 |
| SimCSE | 26.7 | 55.0 | 53.2 | 68.3 | 29.0 | 37.9 | 45.0 |
| CD | 27.0 | 62.7 | 47.7 | 65.4 | 30.6 | 34.5 | 44.7 |
| CT | 28.3 | 55.6 | 49.9 | 63.8 | 30.5 | 35.9 | 44.0 |
A big disadvantage of adaptive pre-training is the high computational overhead, as you must first run pre-training on your corpus and then supervised learning on a labeled training dataset. The labeled trained datasets can be quite large (e.g. the all-*-v1 models had been trained on over 1 billion training pairs).
GPL: Generative Pseudo-Labeling
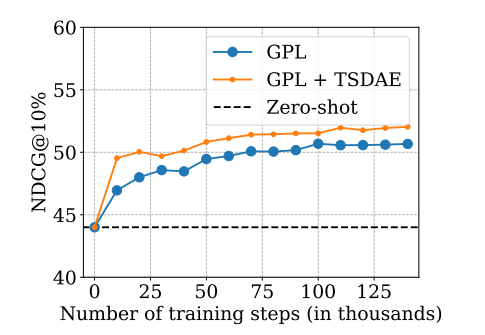
GPL overcomes the aforementioned issue: It can be applied on-top of a fine-tuned model. Hence, you can use one of the pre-trained models and adapt it to your specific domain:

The longer you train, the better your model gets. In our experiments, we were training the models for about 1 day on a V100-GPU. GPL can be combined with adaptive pre-training, which can give another performance boost.
GPL Steps
GPL works in three phases:
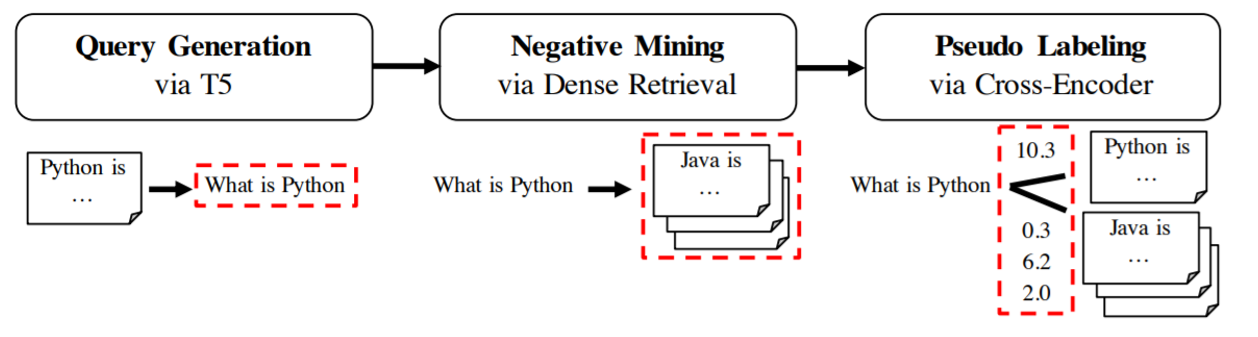
Query Generation: For a given text from our domain, we first use a T5 model that generates a possible query for the given text. E.g. when your text is “Python is a high-level general-purpose programming language”, the model might generate a query like “What is Python”. You can find various query generators on our doc2query-hub.
Negative Mining: Next, for the generated query “What is Python” we mine negative passages from our corpus, i.e. passages that are similar to the query but which a user would not consider relevant. Such a negative passage could be “Java is a high-level, class-based, object-oriented programming language.”. We do this mining using dense retrieval, i.e. we use one of the existing text embedding models and retrieve relevant paragraphs for the given query.
Pseudo Labeling: It might be that in the negative mining step we retrieve a passage that is actually relevant for the query (like another definition for “What is Python”). To overcome this issue, we use a Cross-Encoder to score all (query, passage)-pairs.
Training: Once we have the triplets (generated query, positive passage, mined negative passage) and the Cross-Encoder scores for (query, positive) and (query, negative) we can start training the text embedding model using MarginMSELoss.
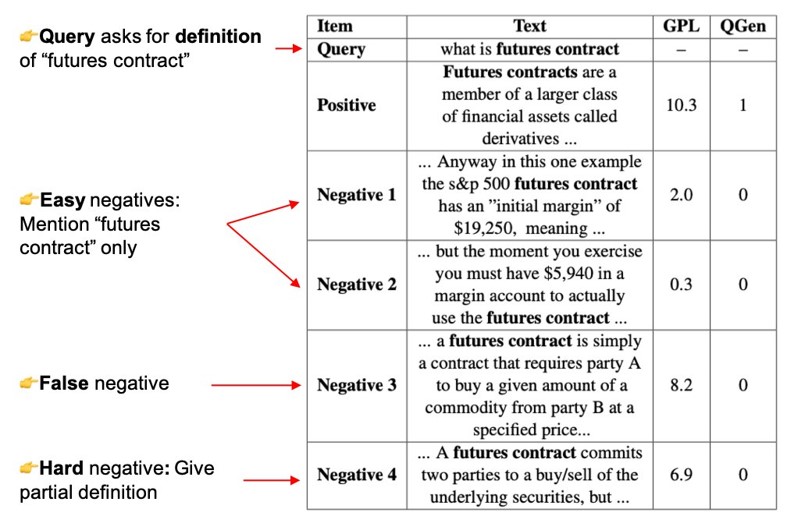
The pseudo labeling step is quite important and which results in the increased performance compared to the previous method QGen, which treated passages just as positive (1) or negative (0). As we see in the following picture, for a generate query (“what is futures contract”), the negative mining step retrieves passages that are partly or highly relevant to the generated query. Using MarginMSELoss and the Cross-Encoder, we can identify these passages and teach the text embedding model that these passages are also relevant for the given query.
The following tables gives an overview of GPL in comparison to adaptive pre-training (MLM and TSDAE). As mentioned, GPL can be combined with adaptive pre-training.
| Approach | FiQA | SciFact | BioASQ | TREC-COVID | CQADupStack | Robust04 | Avg |
|---|---|---|---|---|---|---|---|
| Zero-Shot model | 26.7 | 57.1 | 52.9 | 66.1 | 29.6 | 39.0 | 45.2 |
| TSDAE + GPL | 33.3 | 67.3 | 62.8 | 74.0 | 35.1 | 42.1 | 52.4 |
| GPL | 33.1 | 65.2 | 61.6 | 71.7 | 34.4 | 42.1 | 51.4 |
| TSDAE | 29.3 | 62.8 | 55.5 | 76.1 | 31.8 | 39.4 | 49.2 |
| MLM | 30.2 | 60.0 | 51.3 | 69.5 | 30.4 | 38.8 | 46.7 |
GPL Code
You can find the code for GPL here: https://github.com/UKPLab/gpl
We made the code simple to use, so that you just need to pass your corpus and everything else is handled by the training code.
Citation
If you find these resources helpful, feel free to cite our papers.
@inproceedings{wang-2021-TSDAE,
title = "TSDAE: Using Transformer-based Sequential Denoising Auto-Encoderfor Unsupervised Sentence Embedding Learning",
author = "Wang, Kexin and Reimers, Nils and Gurevych, Iryna",
booktitle = "Findings of the Association for Computational Linguistics: EMNLP 2021",
month = nov,
year = "2021",
address = "Punta Cana, Dominican Republic",
publisher = "Association for Computational Linguistics",
pages = "671--688",
url = "https://arxiv.org/abs/2104.06979",
}
GPL: Generative Pseudo Labeling for Unsupervised Domain Adaptation of Dense Retrieval:
@inproceedings{wang-2021-GPL,
title = "GPL: Generative Pseudo Labeling for Unsupervised Domain Adaptation of Dense Retrieval",
author = "Wang, Kexin and Thakur, Nandan and Reimers, Nils and Gurevych, Iryna",
journal= "arXiv preprint arXiv:2112.07577",
month = "12",
year = "2021",
url = "https://arxiv.org/abs/2112.07577",
}