Semantic Textual Similarity
Semantic Textual Similarity (STS) assigns a score on the similarity of two texts. In this example, we use the stsb dataset as training data to fine-tune our model. See the following example scripts how to tune SentenceTransformer on STS data:
training_stsbenchmark.py - This example shows how to create a SentenceTransformer model from scratch by using a pre-trained transformer model (e.g.
distilbert/distilbert-base-uncased) together with a pooling layer.training_stsbenchmark_continue_training.py - This example shows how to continue training on STS data for a previously created & trained SentenceTransformer model (e.g.
sentence-transformers/all-mpnet-base-v2).
You can also train and use CrossEncoder models for this task. See Cross Encoder > Training Examples > Semantic Textual Similarity for more details.
Training data
In STS, we have sentence pairs annotated together with a score indicating the similarity. In the original STSbenchmark dataset, the scores range from 0 to 5. We have normalized these scores to range between 0 and 1 in stsb, as that is required for CosineSimilarityLoss as you can see in the Loss Overview.
Here is a simplified version of our training data:
from datasets import Dataset
sentence1_list = ["My first sentence", "Another pair"]
sentence2_list = ["My second sentence", "Unrelated sentence"]
labels_list = [0.8, 0.3]
train_dataset = Dataset.from_dict({
"sentence1": sentence1_list,
"sentence2": sentence2_list,
"label": labels_list,
})
# => Dataset({
# features: ['sentence1', 'sentence2', 'label'],
# num_rows: 2
# })
print(train_dataset[0])
# => {'sentence1': 'My first sentence', 'sentence2': 'My second sentence', 'label': 0.8}
print(train_dataset[1])
# => {'sentence1': 'Another pair', 'sentence2': 'Unrelated sentence', 'label': 0.3}
In the aforementioned scripts, we directly load the stsb dataset:
from datasets import load_dataset
train_dataset = load_dataset("sentence-transformers/stsb", split="train")
# => Dataset({
# features: ['sentence1', 'sentence2', 'score'],
# num_rows: 5749
# })
Loss Function
We use CosineSimilarityLoss as our loss function.
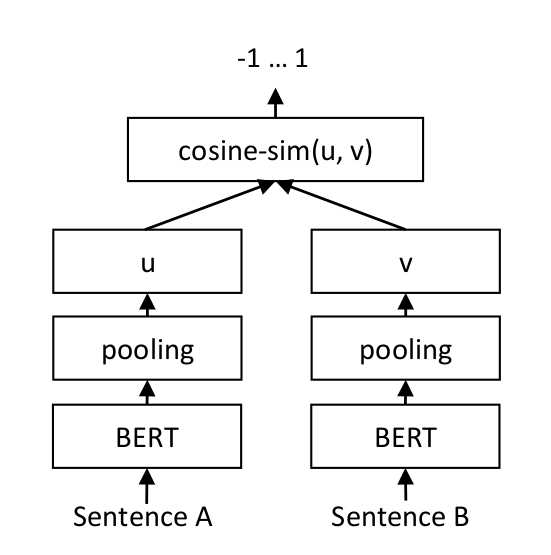
For each sentence pair, we pass sentence A and sentence B through the BERT-based model, which yields the embeddings u und v. The similarity of these embeddings is computed using cosine similarity and the result is compared to the gold similarity score. Note that the two sentences are fed through the same model rather than two separate models. In particular, the cosine similarity for similar texts is maximized and the cosine similarity for dissimilar texts is minimized. This allows our model to be fine-tuned and to recognize the similarity of sentences.
For more details, see Sentence-BERT: Sentence Embeddings using Siamese BERT-Networks.
CoSENTLoss and AnglELoss are more modern variants of CosineSimilarityLoss that accept the same data format of a sentence pair with a similarity score ranging from 0.0 to 1.0. Informal experiments indicate that these two produce stronger models than CosineSimilarityLoss.