Matryoshka Embeddings
See also
See the 🪆 Introduction to Matryoshka Embedding Models blogpost for a narrative walkthrough of the concept, the training loop, and the resulting quality-vs-dimension trade-offs.
Dense embedding models typically produce embeddings with a fixed size, such as 768 or 1024. All further computations (clustering, classification, semantic search, retrieval, reranking, etc.) must then be done on these full embeddings. Matryoshka Representation Learning revisits this idea, and proposes a solution to train embedding models whose embeddings are still useful after truncation to much smaller sizes. This allows for considerably faster (bulk) processing.
Use Cases
A particularly interesting use case is to split up processing into two steps: 1) pre-processing with much smaller vectors and then 2) processing the remaining vectors as full size (also called “shortlisting and reranking”). Additionally, Matryoshka models will allow you to scale your embedding solutions to your desired storage cost, processing speed and performance.
Results
Let’s look at the actual performance that we may be able to expect from a Matryoshka embedding model versus a regular embedding model. For this experiment, I have trained two models:
tomaarsen/mpnet-base-nli-matryoshka: Trained by running matryoshka_nli.py with microsoft/mpnet-base.
tomaarsen/mpnet-base-nli: Trained by running a modified version of matryoshka_nli.py where the training loss is only
MultipleNegativesRankingLossrather thanMatryoshkaLosson top ofMultipleNegativesRankingLoss. I also use microsoft/mpnet-base as the base model.
Both of these models were trained on the AllNLI dataset, which is a concatenation of the SNLI and MultiNLI datasets. I have evaluated these models on the STSBenchmark test set using multiple different embedding dimensions. The results, obtained by running matryoshka_eval_stsb.py, are plotted in the following figure:
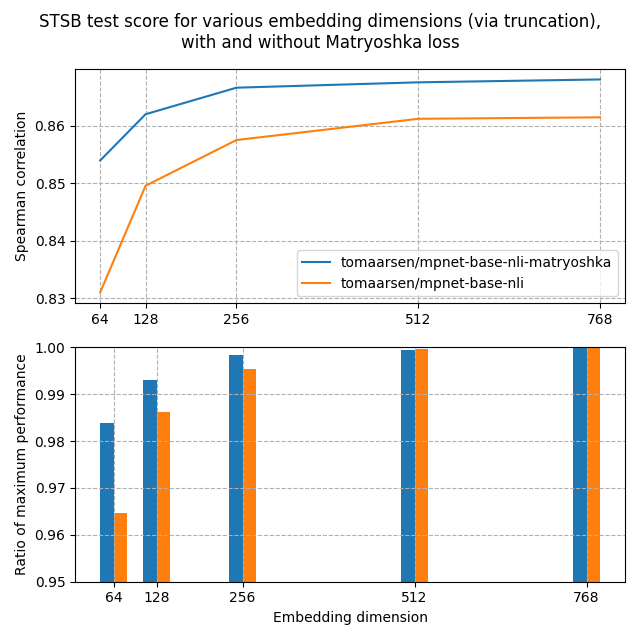
In the top figure, you can see that the Matryoshka model reaches a higher Spearman similarity than the standard model at all dimensionalities, indicative that the Matryoshka model is superior in this task.
Furthermore, the performance of the Matryoshka model falls off much less quickly than the standard model. This is shown clearly in the second figure, which shows the performance at the embedding dimension relative to the maximum performance. Even at 8.3% of the embedding size, the Matryoshka model preserves 98.37% of the performance, much higher than the 96.46% by the standard model.
These findings are indicative that truncating embeddings by a Matryoshka model could: 1) significantly speed up downstream tasks such as retrieval and 2) significantly save on storage space, all without a notable hit in performance.
Training
Training using Matryoshka Representation Learning (MRL) is quite elementary: rather than applying some loss function on only the full-size embeddings, we also apply that same loss function on truncated portions of the embeddings. For example, if a model has an embedding dimension of 768 by default, it can now be trained on 768, 512, 256, 128, 64 and 32. Each of these losses will be added together, optionally with some weight:
from sentence_transformers import SentenceTransformer
from sentence_transformers.sentence_transformer.losses import CoSENTLoss, MatryoshkaLoss
# Loading in fp32 is preferred for training if your memory can handle it
model = SentenceTransformer("microsoft/mpnet-base", model_kwargs={"torch_dtype": "float32"})
base_loss = CoSENTLoss(model=model)
loss = MatryoshkaLoss(model=model, loss=base_loss, matryoshka_dims=[768, 512, 256, 128, 64])
Reference:
MatryoshkaLoss
Additionally, this can be combined with the AdaptiveLayerLoss such that the resulting model can be reduced both in the size of the output dimensions, but also in the number of layers for faster inference. See also the Adaptive Layers for more information on reducing the number of model layers. In Sentence Transformers, the combination of these two losses is called Matryoshka2dLoss, and a shorthand is provided for simpler training.
from sentence_transformers import SentenceTransformer
from sentence_transformers.sentence_transformer.losses import CoSENTLoss, Matryoshka2dLoss
model = SentenceTransformer("microsoft/mpnet-base", model_kwargs={"torch_dtype": "float32"})
base_loss = CoSENTLoss(model=model)
loss = Matryoshka2dLoss(model=model, loss=base_loss, matryoshka_dims=[768, 512, 256, 128, 64])
Reference:
Matryoshka2dLoss
Inference
After a model has been trained using a Matryoshka loss, you can then run inference with it using SentenceTransformers.encode.
from sentence_transformers import SentenceTransformer
import torch.nn.functional as F
matryoshka_dim = 64
model = SentenceTransformer(
"nomic-ai/nomic-embed-text-v1.5",
trust_remote_code=True,
truncate_dim=matryoshka_dim,
)
embeddings = model.encode(
[
"search_query: What is TSNE?",
"search_document: t-distributed stochastic neighbor embedding (t-SNE) is a statistical method for visualizing high-dimensional data by giving each datapoint a location in a two or three-dimensional map.",
"search_document: Amelia Mary Earhart was an American aviation pioneer and writer.",
]
)
assert embeddings.shape[-1] == matryoshka_dim
similarities = model.similarity(embeddings[0], embeddings[1:])
# => tensor([[0.7839, 0.4933]])
As you can see, the similarity between the search query and the correct document is much higher than that of an unrelated document, despite the very small matryoshka dimension applied. Feel free to copy this script locally, modify the matryoshka_dim, and observe the difference in similarities.
Note: Despite the embeddings being smaller, training and inference of a Matryoshka model is not faster, not more memory-efficient, and not smaller. Only the processing and storage of the resulting embeddings will be faster and cheaper.
Code Examples
See the following scripts as examples of how to apply the MatryoshkaLoss in practice:
matryoshka_nli.py: This example uses the MultipleNegativesRankingLoss with MatryoshkaLoss to train a strong embedding model using Natural Language Inference (NLI) data. It is an adaptation of the NLI documentation.
matryoshka_nli_reduced_dim.py: This example uses the MultipleNegativesRankingLoss with MatryoshkaLoss to train a strong embedding model with a small maximum output dimension of 256. It trains using Natural Language Inference (NLI) data, and is an adaptation of the NLI documentation.
matryoshka_eval_stsb.py: This example evaluates the embedding model trained with MatryoshkaLoss in matryoshka_nli.py on the test set of the STSBenchmark dataset, and compares it to a non-Matryoshka trained model.
matryoshka_sts.py: This example uses the CoSENTLoss with MatryoshkaLoss to train an embedding model on the training set of the STSBenchmark dataset. It is an adaptation of the STS documentation.
And the following scripts to see how to apply Matryoshka2dLoss:
2d_matryoshka_nli.py: This example uses the
MultipleNegativesRankingLosswithMatryoshka2dLossto train a strong embedding model using Natural Language Inference (NLI) data. It is an adaptation of the NLI documentation.2d_matryoshka_sts.py: This example uses the
CoSENTLosswithMatryoshka2dLossto train an embedding model on the training set of the STSBenchmark dataset. It is an adaptation of the STS documentation.