SimCSE
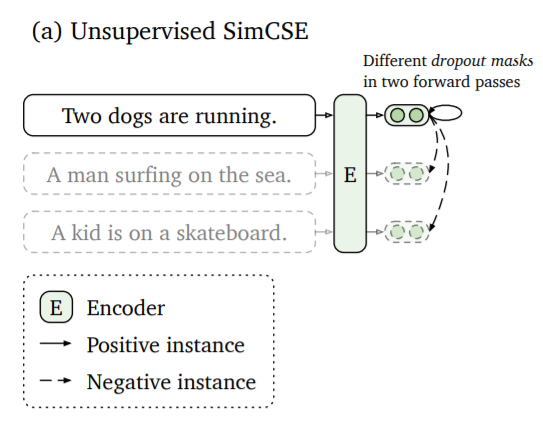
Gao et al. present in SimCSE a simple method to train sentence embeddings without having training data.
The idea is to encode the same sentence twice. Because transformer models apply dropout, the two sentence embeddings end up at slightly different positions. The distance between these two embeddings will be minimized, while the distance to other embeddings of the other sentences in the same batch will be maximized (they serve as negative examples).
Usage with SentenceTransformers
SentenceTransformers implements the MultipleNegativesRankingLoss, which makes training with SimCSE trivial:
from datasets import Dataset
from sentence_transformers import (
SentenceTransformer,
SentenceTransformerTrainer,
SentenceTransformerTrainingArguments,
)
from sentence_transformers.sentence_transformer.losses import MultipleNegativesRankingLoss
from sentence_transformers.sentence_transformer.modules import Pooling, Transformer
# Define your sentence transformer model using mean pooling
model_name = "distilbert/distilroberta-base"
word_embedding_model = Transformer(model_name, max_seq_length=32)
pooling_model = Pooling(word_embedding_model.get_embedding_dimension())
model = SentenceTransformer(modules=[word_embedding_model, pooling_model])
# Define a list with sentences (1k - 100k sentences)
train_sentences = [
"Your set of sentences",
"This is an example sentence",
"And here is another one",
"You should provide at least 1k sentences",
]
# Use the same sentence as both columns, dropout gives the positive pair.
train_dataset = Dataset.from_dict({"sentence1": train_sentences, "sentence2": train_sentences})
# Use MultipleNegativesRankingLoss with in-batch negatives
train_loss = MultipleNegativesRankingLoss(model)
# Configure training
args = SentenceTransformerTrainingArguments(
output_dir="output/simcse-model",
num_train_epochs=1,
per_device_train_batch_size=128,
save_strategy="no",
)
# Train
trainer = SentenceTransformerTrainer(
model=model,
args=args,
train_dataset=train_dataset,
loss=train_loss,
)
trainer.train()
model.save_pretrained("output/simcse-model")
SimCSE from Sentences File
train_simcse_from_file.py loads sentences from a provided text file (plain text or gzipped). One sentence per line is expected.
SimCSE will be training using these sentences. Checkpoints are stored every 10% of training to the output folder.
Training Examples
train_askubuntu_simcse.py - Shows the example how to train with SimCSE on the AskUbuntu Questions dataset.
train_stsb_simcse.py - This script uses 1 million sentences and evaluates SimCSE on the STSbenchmark dataset.
Ablation Study
We use the evaluation setup proposed in our TSDAE paper.
Using mean pooling, with max_seq_length=32 and batch_size=128
| Base Model | AskUbuntu Test-Performance (MAP) |
|---|---|
| distilbert/distilbert-base-uncased | 53.59 |
| google-bert/bert-base-uncased | 54.89 |
| distilbert/distilroberta-base | 56.16 |
| FacebookAI/roberta-base | 55.89 |
Using mean pooling, with max_seq_length=32 and distilbert/distilroberta-base model.
| Batch Size | AskUbuntu Test-Performance (MAP) |
|---|---|
| 128 | 56.16 |
| 256 | 56.63 |
| 512 | 56.69 |
Using max_seq_length=32, distilbert/distilroberta-base model, and 512 batch size.
| Pooling Mode | AskUbuntu Test-Performance (MAP) |
|---|---|
| Mean pooling | 56.69 |
| CLS pooling | 56.56 |
| Max pooling | 52.91 |
Note: This is a re-implementation of SimCSE within sentence-transformers. For the official SimCSE code, see: princeton-nlp/SimCSE