GenQ
In our paper BEIR: A Heterogeneous Benchmark for Zero-shot Evaluation of Information Retrieval Models we presented a method to adapt a model for asymmetric semantic search for a corpus without labeled training data.
Background
In asymmetric semantic search, the user provides a (short) query like some keywords or a question. We then want to retrieve a longer text passage that provides the answer.
For example:
query: What is Python?
passage to retrieve: Python is an interpreted, high-level and general-purpose programming language. Python's design philosophy emphasizes code readability with its notable use of significant whitespace. Its language constructs and object-oriented approach aim to help programmers write clear, logical code for small and large-scale projects.
We showed how to train such models when sufficient training data (query & relevant passage) is available here: Training MS MARCO dataset
In this tutorial, we show how to train such models if no training data is available, i.e., if you don’t have thousands of labeled query & relevant passage pairs.
Overview
We use synthetic query generation to achieve our goal. We start with the passage from our document collection and create possible queries that users might ask or search for.
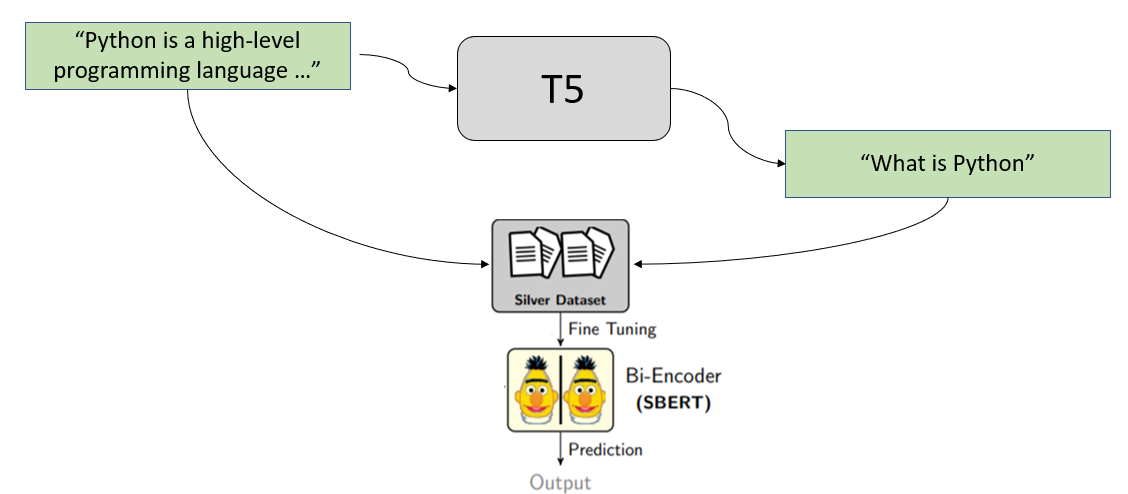
For example, we have the following text passage:
Python is an interpreted, high-level and general-purpose programming language. Python's design philosophy emphasizes code readability with its notable use of significant whitespace. Its language constructs and object-oriented approach aim to help programmers write clear, logical code for small and large-scale projects.
We pass this passage through a specially trained T5 model which generates possible queries for us. For the above passage, it might generate these queries:
What is python
definition python
what language uses whitespaces
We then use these generated queries to create our training set:
(What is python, Python is an interpreted...)
(definition python, Python is an interpreted...)
(what language uses whitespaces, Python is an interpreted...)
And train our SentenceTransformer bi-encoder with it.
Query Generation
In BeIR we provide different models that can be used for query generation. In this example, we use the T5 model that was trained by docTTTTTquery:
from transformers import T5Tokenizer, T5ForConditionalGeneration
import torch
tokenizer = T5Tokenizer.from_pretrained("BeIR/query-gen-msmarco-t5-large-v1")
model = T5ForConditionalGeneration.from_pretrained("BeIR/query-gen-msmarco-t5-large-v1")
model.eval()
para = "Python is an interpreted, high-level and general-purpose programming language. Python's design philosophy emphasizes code readability with its notable use of significant whitespace. Its language constructs and object-oriented approach aim to help programmers write clear, logical code for small and large-scale projects."
input_ids = tokenizer.encode(para, return_tensors="pt")
with torch.no_grad():
outputs = model.generate(
input_ids=input_ids,
max_length=64,
do_sample=True,
top_p=0.95,
num_return_sequences=3,
)
print("Paragraph:")
print(para)
print("\nGenerated Queries:")
for i in range(len(outputs)):
query = tokenizer.decode(outputs[i], skip_special_tokens=True)
print(f"{i + 1}: {query}")
In the above code, we use Top-p (nucleus) sampling which will randomly pick a word from a collection of likely words. As a consequence, the model will generate different queries each time.
Bi-Encoder Training
With the generated queries, we can then train a bi-encoder using the use MultipleNegativesRankingLoss.
Full Example
We train a semantic search model to search through Wikipedia articles about programming articles & technologies.
We use the text paragraphs from the following Wikipedia articles: Assembly language, C , C# , C++, Go , Java , JavaScript, Keras, Laravel, MATLAB, Matplotlib, MongoDB, MySQL, Natural Language Toolkit, NumPy, pandas (software), Perl, PHP, PostgreSQL, Python , PyTorch, R , React, Rust , Scala , scikit-learn, SciPy, Swift , TensorFlow, Vue.js
In:
1_programming_query_generation.py - We generate queries for all paragraphs from these articles
2_programming_train_bi_encoder.py - We train a SentenceTransformer bi-encoder with these generated queries. This results in a model we can then use for semantic search (for the given Wikipedia articles).
3_programming_semantic_search.py - Shows how the trained model can be used for semantic search.